



빅데이터 분석기획 → 빅데이터 탐색 → 빅데이터모델링→ 빅데이터 결과해석
| Part1 : 빅데이터 분석 기획 |
빅데이터의 이해 → 빅데이터 분석 기획 → 데이터수집 및 저장계획
| Hot keyword | |||
| ETL, 가트너 3V, 데이터사이언티스트, 데이터웨어하우스(DW), 빅데이터 가치, 마이데이터 딥러닝, 분석5단계, 지도학습, 비식별화, 개인정보보호법, 데이터거버넌스, 하둡, GDPR, API게이트웨이, 스파크, EDA, 데이터분석기획절차, 접근방법, 모델링, 진단분석, 분석성숙도, 시급성 이상값, 데이터 수집 정형데이터 품질 보증, 민감정보, 데이터 품질 Nosql, HDFS, 제타바이트 |
|||
ch1. 빅데이터의 이해
(1) 빅데이터 개요 및 활용
| 01 | 데이터와 정보 | ||
| 1. 데이터 : 추론과 추정의 근거를 이루는 사실(fact) 존재적 특성 + 당위적 특성 2. 데이터의 종류 → 구분하는 이유 - 단변량 vs 다변량 - 질적자료 vs 수치(양적) 자료 - 횡단면자료 vs 시계열자료 vs 종적자료 3. 데이터 유형 : 정형, 반정형, 비정형 4. 데이터 기능 : 암묵지, 형식지 → 지식창조 매커니즘(공통화, 표출화, 연결화, 내면화) 5. 지식의 피라미드(DIKW) : 데이터(data) → 정보(information) → 지식(knowledge) → 지혜(wisdom) |
|||
데이터의 종류:
횡단면 자료: 여러 개의 관측물을 한 번에 관측
시계열 자료: 하나의 관측물을 시간에 흐름에 따라 계속 관측
종적 자료: 횡단면+시계열; 여러 개의 관측물을 시간에 흐름에 따라 계속 관측
데이터 유형:
정형: 2차원(표), 스키마(규칙)
비정형: (이미지, pdf, 음성 파일, 텍스트 파일)
반정형: 스키마이면서 데이터 구조가 유연한 데이터 유형 ex) html, xml, json, rdf
예상 질문: ~한 데이터 구조가 ~핮ㄴ 데이터 유형은?
| 02 | 데이터베이스 | ||
| 1. 데이터베이스 정의 2. 데이터베이스 특징 : 통합, 저장, 공용, 변화 3. 데이터베이스 관리시스템 : DBMS + SQL 4. 경영에서의 데이터베이스 활용 : (1980년대) OLTP, OLAP, (2000년대) CRM, SCM 5. 데이터웨어하우스 : 주제지향, 통합성, 시계열성, 비휘발성 6. 데이터웨어하우스 구성 : 데이터모델, ETL, ODS, 메타, OLAP, 데이터마이닝, 경영기반솔류션 |
|||
예상 출제 스타일: 3, 4 개념 자체 X, 문제의 예문/예시 문단에서 나옴
데이터 모델 -> ERD(Entity Relationship Diagram)
ETL(Extract Transform Loading) 추출 변형 적재
데이터 웨어하우스의 용도: 분석
데이터베이스의 용도: 운영
| 03 | 빅데이터 개요 | ||
| 1. 빅데이터의 정의 2. 빅데이터 등장배경 : 데이터변화 , 기술 변화, 인재, 조직변화 3. 빅데이터에 따른 변화 : 사전→사후처리, 표본→전수조사, 데이터 질→양, 인과관계→상관관계 4. 빅데이터의 특징 : (3V) 규모, 유형, 속도 + 품질, 가치 5. 빅데이터를 활용하기 위한 3요소 : 자원, 기술, 인력 |
|||
| 04 | 빅데이터 가치/산업의 이해 | ||
| 1. 빅데이터의 기능과 효과 2. 빅테이터 가치 측정의 어려움 : 데이터활용방식, 가치창출방식, 분석 기술발전, 데이터 수집원가 3. 데이터 산업 발전 : 데이터 처리→ 데이터 통합 → 데이터 분석 → 데이터 연결 → 데이터 권리 시대 |
|||
| 05 | 빅데이터 조직/인력 | ||
| 1. 조직의 구성 : 집중형, 기능형, 분산형 2. 데이터 사이언스 역량 3. 데이터사 이언티스트 |
|||
예상 질문:
~한 상황에서 맞는 조직의 구성은?
조직 구성의 장단점?
빅데이터의 조직/인력:
조직의 구성:
집중형: 분석 전담 조직이 각 부서의요청 사항을 수집함 -> 장점: 전략적 중요도에 따라 우선순위 결정
기능형: 각 부서에서 해결 -> 단점: 전략적X
분산형: 집중형+기능형 -> 단점: 사람 많이 필요함
(2) 빅데이터 기술 및 제도
| 01 | 빅데이터 플랫폼 | ||
| 1. 빅데이터 플랫폼이란 2. 플랫폼 등장배경 : 미즈니스 요구사항 변화, 데이터 규모와 처리 복잡도 증가, 데이터 구조의 변화와 신속성 요구, 데이터 분석 유연성 증대 3. 플랫폼의 구조 : 소프트웨어 계층, 플랫폼 계층, 인프라스트럭쳐 계층 |
|||
Fun Fact: 빅데이터 -> 검색 엔진 -> only 구글 -> 검색 결과에 비정형 데이터(음악, 이미지) 포함 시킴 -> 사이트가 가진 모든 정보 수집 -> 유저가 필요한 정보 보여줌
| 02 | 빅데이터 처리 기술 | ||
| 1. 빅데이터 처리과정과 기술 : 생성 → 수집 → 저장 → 처리 → 분석 → 시각화 2. 각 단계의 기술과 기술을 실행하는 프로그램 |
|||
수집: ETL, 크롤링
| 03 | 빅데이터와 인공지능 | ||
| 1. 인공지능의 정의 2. 인공지능과 머신러닝(기계학습) 및 딥러닝의 관계 3. 인공지능의 기술 동향 |
|||
| 04 | 개인정보 개요/법.제도/ 식별화/ 활용 | ||
| 1. 개인정보의 정의 2. 빅데이터 개인정보보호 가이드라인(방송통신위원회) 3. 개인정보 법.제도 : 개인정보보호법, 정보통신망법, 신용정보법 4. 데이터3법의 주요개정 내용 : 가명정보 개념 도입 5. 개인정보 비식별화조치 가이드라인 : 사전검토, 비식별조치, 적정성평가, 사후관리 6. 개인정보활용 : 데이터 수집/활용/처리의 위기 요인 및 통제방안 |
|||
ch2. 데이터 분석 계획
(1) 분석방안 수립
| 01 | 데이터 분석 기획 | ||
| 1. 데이터 분석 정의 2. 데이터 분석 기획 특징 : 분석대상과 방법에 따른 분류 3. 분석과제의 우선순위 평가 및 로드맵 설정 |
|||
| 02 | 분석 문제 정의 | ||
| 1. 분석 문제 정의 개요 2. 하향식 접근 방식 3. 상향식 접근 방식 |
|||
| 03 | 데이터 분석 방안 | ||
| 1. 분석방법론 및 계층적 프로세스 모델 구성 2. KDD 분석 방법론 : 데이터셋 선택→ 전처리 → 변환 →데이터 마이닝 →데이터마이닝 결과 평가 3. CRISP-DM 방법론 : 업무이해 →데이터 이해 → 데이터 준비 →모델링 → 평가 → 전개 4. SEMMA 방법론 : 추출 → 탐색 → 수정 →모델링 → 평가 |
|||
| 04 | 빅데이터 분석방법론 및 거버넌스 | ||
| 1. 방법론 : 분석기회 → 데이터 준비 → 데이터 분석 → 시스템 구현 → 평가 및 전개 2. 데이터 거버넌스 3. 데이터 분석 수준 진단 |
|||
(2) 분석 작업 계획
ch3. 데이터 수집 및 저장계획
(1) 데이터 수집 및 전환
| 01 | 데이터 수집 | ||
| 1. 비즈니스 도메인과 원천 데이터 정보 수집 2. 내 외부 데이터 수집 3. 데이터 수집 기술 정형데이터 : ETL, FTP, API, DBToDB, 스쿱 비정형데이터 : 크롤링, RSS, Open API, 척화, 카프카 반정형 : 플럼, 스크라이브, 센싱, 스트리밍 |
|||
예상 질문:
객관식: 다음 중 정형데이터 수집 기술이 아닌 것은?
관계형 DB와 하둡 DB가 데이터 전송을 할 때 쓰이는 기술은? Sqoop(스쿱)
인터넷 상 존재하는 웹문서의 정보를 수집하는 기술은? 크롤링(Crawling)
정형:
FTP(File Transfer Protocol): 기업 간의 제휴(파리 바게트 - 통신사 할인 이벤트: 고객 정보 공유)
API(Application Programming Interface): 오픈 뱅킹(국민-신한-토스: 어떤 앱에서도 다른 은행의 정보를 알 수 있음; 같은 형태의 데이터를 상호교환)
DBtoDB:
스쿱(Sqoop):
비정형: 형식이 자유로움 하지만 스키마(규칙)가 없음
크롤링(Crawling): 뉴스, 계시판 같은 웹문서의 정보를 수집하는 기술
RSS(Rich Site Summary):
Open API:
반정형: 형식이 자유로움 하지만 스키마 존재 ex) html, xml, json(javascript object notation)
| 02 | 데이터 유형 및 속성 | ||
| 1. 데이터 유형 : 정형, 비정형, 반정형 2. 데이터 저장 방식 : 파일시스템, 관계형데이터베이스, 분산처리데이터베이스 3. 데이터 적절성 검증 |
|||
데이터 저장 방식:
기존 data 처리: 집중형
빅데이터 처리: 분산형 -> 처리 속도가 빠름
데이터 적절성 검증:
키 값: 데이터 고유의 번호(중복X, 결측X)
데이터의 오류 검증
| 03 | 데이터 변환 | ||
| 1. 데이터변환방식 2. 데이터베이스 구조설계 3. 비정형/반정형 데이터 변환 |
|||
| 04 | 데이터 비식별화 | ||
| 1. 비식별화 개요 : 식별자와 속성자 2. 비식별화 조치 방법 : 가명처리, 총계처리, 데이터 삭제, 데이터범주화, 데이터마스킹 3. 적정성평가 : 익명성, 다양성, 근접성 |
|||
예상 질문: 데이터의 비식별화 무조건/제일 많이 나옴!!!
Data: 식별자, 속성자
식별자: 한 데이터를 바로 특정할 수 있음
속성자: 데이터를 그룹으로 구분
개인정보가 유출되기 때문에 비식별화 해줌
식별자는 원칙적으로는 삭제 but 반드시는 아님
분석에 쓰이지 않는 데이터는 삭제 또는 비식별화 조치 해줌
가명처리: 식별 요소 중 몇개를 다른 값으로 대체
총계처리: 개별 값X, 전체 값으로 대체(sum, 평균)
범주화: 36살 -> 30대
마스킹: 김재홍 -> 김0홍, 김**
실무: (상하단 처리: 극단치 처리)
적정성 평가:
익명성: K-익명성(변수 중심) => 관측치가 n명이면 비식별화 후 동일한 값이 K개 이상은 나타나야 함 b/c 빈도분석
다양성: L-다양성 (개체 중심) => L개 이상 가져야 함
근접성: t-근접성: 전체 모집단의 분포와 샘플의 분포가 비슷해야 함
(2) 데이터 적재 및 저장
| 01 | 데이터 적재 | ||
| 1. 데이터 적재 도구 - 데이터 수집도구 : 플루언티드, 플럼, 스크라이브 등 - NOSQL DBMS가 제공하는 도구 - 관계형 DBMS 의 데이터를 NOSQL DBMS에 적재 |
|||
SQL: 적재+저장 한 번에 일어남
create - 저장
select - 적재
insert - 적재
from - 원천
| 02 | 데이터 저장 | ||
| 1. 정형 - 관계형데이터베이스(RDB) oracle, MSSQL, MySQL 2. 반정형 - NoSQL MongoDB, cassandra, Hbase 3. 비정형- 분산파일시스템 HDFS, GFS |
|||
위 용어들 숙지
1단원 끝
데이터 수집 - 적재+저장
2단원 시작
데이터 전처리
빅데이터 분석기획 → 빅데이터 탐색 → 빅데이터모델링→ 빅데이터 결과해석
| Part2 : 빅데이터 탐색 |
데이터 전처리 → 데이터 탐색 → 통계기법 이해
| Hot keyword | |||
| 데이터 정제, 변수선택, 파생변수생성, 학습데이터 불균형, 차원의 저주, 군집불균형, 차원축소, 변수변환 박스플랏, 산점도, 상관계수, median, 표본추출, 왜도. 기초통계량, 이상치 주성분분석, 비정형데이터 전수조사, 불량률, 확률계산, 층화추출, 확률분포, 포아송분포, 중심극한정리, 군집추출, 층화추출, 카이제곱, 확률밀도함수 최대우도, z계산, 점추정, 1/2종 오류, 유의수준, 표본분산 |
|||
ch1. 데이터 전처리
(1) 데이터 정제
| 01 | 데이터에 대한 이해 | ||
| 1. 데이터 내재된 특성 : 단위, 관측값, 변수, 원자료 2. 데이터의 종류 - 단변량 vs 다변량 - 질적자료 vs 수치(양적) 자료 - 횡단면자료 vs 시계열자료 vs 종적자료 3. 데이터 정제 - 수집된 데이터 분석에 필요한 데이터로 추출/통합 - 비정형데이터 → 정형데이터 변환 |
|||
| 02 | 데이터 결측치 처리 | ||
| 1. 결측치의 의미 2. 결측데이터의 종류 3. 결측값 유형의 분석 및 대치 - 단순대치법 : 완전분석, 평균대치, 회귀대치, 단순확률대치, 최근접대치 - 다중대치법 : (통계적효율성, 일치성 보완) 대치단계 → 분석단계 → 결합단계 |
|||
원래 관측됐어야하는데 -> 미싱 -> 규묘에 따라 삭제/그룹화/대체 할 수 있음
미싱이 가능 -> 그 자체가 그룹(속성)이 됨 ex) 집 전화번호
| 03 | 데이터이상치 처리 | ||
| 1. 이상치의 정의 2. 이상치의 종류 및 발생원인 - 단변수이상치, 다변수이상치 - (원인) 비자연적 : 인력실수, 측정오류, 실험오류, 의도적이상치, 자료처리오류, 표본오류 vs 자연적이상치 3. 이상치가 미치는 영향 4. 이상치 탐지방법 - 시각화 : 상자그림, 줄기잎그림, 산점도 - z스코어 - 밀도기반 클러스터링 방법, 고립의사나무 방법 |
|||
상자그림(Box Plot): Q3*1.5 | Q3(상위 75%) | Q2(중위수) | Q1(하위 25%) | Q1*1.5
산점조(Scatter Plot): 2개의 변수, 둘 다 연속형 자료일 때
z스코어: 표준화 점수(ex: 수능 표준 점수), 뮤+3시그마(99.7%) 밖에 벗어나는 것들이 이상치
(2) 분석변수 처리
| 01 | 변수 선택 | ||
| 1. 회귀분석 방법 : 전체모형, 축소모형, 영모형 비교 2. 선택방법 : 전진선택법, 후진선택법, 단계적선택법 |
|||
전체 모형: 모든 변수
축소 모형: 중요 변수만
영모형: 선택된 변수가 없음
전체와 축소는 비슷해야 함 하지만 영모형보다는 설명이 잘 돼야 함(영모형과 비슷하면 쓸모가 없음)
| 02 | 차원 축소 | ||
| 1. 차원축소 필요성 : 복잡도의 축소, 과적합방지, 해석력 확보, 차원의 저주 해결 2. 차원 축소 방법 : 요인분석, 주성분 분석 |
|||
| 03 | 파생변수의 생성 | ||
| 1. 기존의 변수를 조합하여 새로운 변수를 만들어 내는 것 2. 요약변수 vs 파생변수 2. 파생변수 생성시 유의사항 : 처리 단위 일관성, 결측치 처리 등 |
|||
| 04 | 변수변환 | ||
| 1. 데이터를 분석하기 좋은 형태로 변환 2. 변환방법 : 연속형 → 범주형(해석용이), 정규화(스케일), 로그변환, 역수변환, 지수,제곱근, 정규분포변환 |
|||
| 05 | 불균형데이터 처리 | ||
| 불균형데이터란 ? 각 클래스가 가지고 있는 양에 차이(예, 질병환자 보유) 문제점 : 모형의 성능판별 특히, 재현율이 급격히 작아지는 현상 처리방법 - 가중치 균형(고정비율, 최적비율 이용) → 손실에 동일하게 기여 - 언더샘플링 vs 오버샘플링 |
|||
회귀 모형 vs 판별 모형
회귀 모형
| ID | 아파트 가격(예측 하는 값) | 평 수 | 층 수 | 브랜드 | 지역 | 지하철 거리 |
판별 모형
| ID | 성별(예측하는 값 | 머리 길이 | 키 |
남자 99 / 여자 1
=> 불균형 데이터
오버샘플링: 부족한 데이터를 중복 사용
ch2. 데이터 탐색
(1) 데이터 탐색의 기초
| 01 | 탐색 개요 | ||
| 1. 탐색적 데이터 분석 : EDA(Exploratory Data Analysis) 2. 분석 필요성 및 과정 3. 이상치 검출 - 개별 데이터 관찰 - 통계값 활용 : 평균, 중앙값, 최빈값, 범위, 분산, IQR(사분위수 범위) - 시각화 : 히스토그램, 점플랏, 확률밀도함수 - 머신러닝 방법 : K-means 를 통해 거리 측정 |
|||
중심값: 평균(극단치의 영향을 많이 받음), 중앙값(순서 나열), 최대값, 최소값, 최빈값
산포: 분산, 표준편차
분위수: 백분위수, 사분위수, 범위(max-min), 사분위범위(Q3-Q1; 극단치 제외)
=> 이런 계산을 통해 데이터를 어떻게 볼 것인가
| 02 | 상관분석 | ||
| 1. 상관분석 방법 및 해야하는 이유 2. 상관분석의 기본가정 : 선형성, 등분산성, 정규성 3. 피어슨상관관계, 스피어만 상관계수 |
|||
양적 | 질적 자료 -> 탐색/분석 방법 다름 b/c 사칙연산
질적 자료 -> 빈도 분석
피어슨 상관관계: -1<=p<=1
스피어만 상관계수:
| 03 | 기초통계량 추출 | ||
| 1. 중심화 경향 기초 통계량 : 산술 평균, 기하평균, 조화평균, 중앙값, 최빈값, 분위수 2. 산포도 : 분산, 범위, 사분위범위 3. 자료의 형태 : 왜도, 첨도 |
|||
평균:
산술: a+b/2
기하: sqrt(ab)
조화: 2/(1/a+1/b)
자료의 형태:
분포의 형태: 기존 분포 - 정규 분포
왜도 > 0 : 최빈값-중앙값-평균(극단치가 평균을 오른쪽으로 끌고 감)
| 04 | 시각적 데이터 탐색 | ||
| 1. 통계적 시각화 : 도스분포표, 히스토그램, 막대그래프, 파이차트, 산점도, 줄기잎그림, 상자수염 2. 각 시각화 도구의 특징 |
|||
(2) 고급데이터 탐색
| 01 | 시공간데이터 탐색 | ||
| 1. 시공간 데이터의 개념 : 공간적 정보에 흐름(이력) 결합된 다차원 데이터 - 시간데이터 : 유효시간, 거래시간, 스냅샷 - 공간데이터 : 비공간타입, 래스터공간(그리드), 벡터공간(점,선,면), 기하학적타입(거리,면적,길이) 위상적타입(공간객체간의 관계) 2. 시공간데이터 분석 3. 적용 분야 : 지리정보시스템, 위치기반 서비스, 차량위치 추적서비스 |
|||
시공간 데이터: 장소 | 시간 | 관측값 . . .
ex) 네비게이션, 날씨 정보
| 02 | 다변량데이터분석 | ||
| 1. 종속변수와 독립변수 사이의 인과관계 탐색 - 다중회귀 - 로지스틱회귀 - 분산분석 - 다변량 분산분석 2. 변수축약 - 주성분분석 - 요인분석 - 정준상관분석 3. 개체유도 - 군집분석 : 계층적, 비계층적 - 다차원척도법 - 판별분석 |
|||
분산 분석(analysis of variance):
t-분석: 서로 다른 2 그룹의 평균 일치 X ??
F-분석: 서로 다른 3개 이상 그룹의 평균 ??
| 03 | 비정형데이터 탐색 | ||
| 1. 비정형데이터의 특징 : 텍스트중심 + 날짜,숫자 포함, 비구조적데이터 2. 비정형데이터 분석 - 데이터마이닝 - 텍스트마이닝 : 자연어처리, 문장내 주제를 파악 - 오피니언마이닝 : 감정, 뉘앙스, 태도 등을 판별(감정분석) - 웹마이닝 : 웹자원으로부터 의미있는 패턴, 추세 등을 도출 |
|||
ch3. 통계기법의 이해
(1) 기술통계
| 01 | 데이터 요약 | ||
| 기술통계 : 분석에 필요한 데이터를 요약하여 묘사. 설명하는 통계 기법 데이터의 특성을 찾아내고 정량화를 통해 체계적 요약 필요 |
|||
| 02 | 표본추출 | ||
| 1. 모집단, 표본, 표본추출의 개념 2. 전수조사와 표본조사 3. 표본추출 오차 4. 확률표본추출 기법 : 단순무작위, 계통추출, 층화추출, 비확률표본추출(간편추출, 판단추출, 할당추출, 눈덩이 추출) |
|||
| 03 | 확률분포 | ||
| 1. 확률의 개념 : 사건과 표본공간 2. 확률의 성질 3. 조건부확률, 결합확률 4. 베이지안 정리 5. 확률분포(이산형, 연속형) 및 확률분포함수, 확률변수의 기댓값과 분산 6. 이산확률분포 : 이항분포, 다항분포, 포아송분포, 기하분포, 음이항분포, 초기하분포 7. 연속확률분포 : 연속균등분포, 지수분포(포아송분포와 관계, 무기억성), (표준)정규분포, 감마분포, 카이제곱분포, 스튜던트t분포, F분포 |
|||
| 04 | 표본분포 | ||
| 1. 표본평균의 표본분포 ; 평균, 분산 2. 중심극한정리(린데베르그-베리 중심극한정리) 3. 표본평균의 표준화 4. 표본비율의 표본분포 |
|||
(2) 추론통계
| 01 | 통계적 추론 | ||
| 1. 모집단에 대한 미지의 양상을 알기 위해 표본을 활용하여 추측하는 과정 2. 추정과 가설검정 |
|||
| 02 | 점추정/구간추정 | ||
| 1. 추정량의 선택기준 : 불편성, 효율성, 일치성, 충분성 → 최소분산불편추정량(MVUE) 2. 점추정량 3. 추정방법 : 평균제곱오차, 최대우도점추정, 적률방법 3. 구간추정 : 신뢰수준, 유의수준 |
|||
하나의 값으로 추정; point estimate; 점추정 => 정확성 문제
범위/구간(으)로 추정; interval estimate; 구간추정 => 신뢰성 문제
구간을 신뢰수준
유의수준 95%

구간추정 +-2.2%
신뢰수준: 95%
예시: 어떤 사람이 더불어민주당을 지지할 확률이 36.0~40.4%일 확률이 95%
| 03 | 가설검정 | ||
| 1. 가설 설정 : 귀무가설, 대립가설 2. 유의수준 설정 : 1종오류, 2종오류 3. 검정통계량 및 표본분포의 결정 4. 임계치 및 검정통계량 비교 5. 표본의 평균검정, 독립두표본의 평균차이 검정, 대응표본의 평균차이 검정, 단일표본 모분산 검정, 두 모분산비에 대한 가설검정 |
|||
귀무가설: 알고 있던 것으로 돌아가는 것; 표본 통계량이 맞음
대립가설: 표본검증; 표본 통계량이 틀림

1종 오류: 귀무가설이 맞는데 틀렸다고 함
2종 오류: 귀무가설이 틀린데 맞다고 함
빅데이터 분석기획 → 빅데이터 탐색 → 빅데이터모델링→ 빅데이터 결과해석
| Part3 : 빅데이터 모델링 |
분석모형 설계→ 분석기법 적용
| Hot keyword | |||
| 모델링 절차 k-fold 검정, 데이터 분할 변수선택, 인공신경망, 합성곱계층, 잔차진단, SVM, Lasso, 로지스틱회귀분석, 앙상블, 비지도학습, 지도학습-분류, 군집분석, 회귀분석, 활성화함수, 의사결정나무, DNN, CNN, RNN, 초매개변수 자료분석, 다차원척도, 베이즈정리, 시계열자료, 자기상관, 비정형데이터형태, 랜덤포레스트, 비모수적통계검정법, 배깅, 부스팅, ARIMA |
|||
이미 타겟 변수를 가지고 있는 => 지도학습
아파트 각격처럼 종속변수가 연속형이면 => 지도학습 중 회귀
산용등급의 불량 여부처럼 종속변수가 이항변수이면 => 지도학습 중 분류
1. 지도학습 중 회귀
| ID | 아파트가격 | 층 수 | 평 수 | 세대 수 | 특화시설 | 입지 | 교통편 |
아파트가격 예측
사용할 수 있는 모델: 회귀모형/의사결정나무/인공신경망(NN)/SVM/앙상블
2. 지도학습 중 분류
| ID | 신용등급 | 사용기간 | 연봉 | 직업 |
| 0 | ||||
| 1 |
정상or불량일 확률 예측
사용할 수 있는 모델: 로지스틱회귀(결과가 0 또는 1인것)/의사결정나무/NN/SVM/앙상블
3. 개체만 있는 데이터 => 비지도 학습 중 군집 분석
| ID | 구입횟수 | 구매금액 | 최근 사용 일시 |
비슷한 성향을 보이는 고객군 탐색
4. 고객이 산 물품 정보만 있는 데이터 => 비지도 학습 중 연관성 분석
| ID | 물품 | 금액 | 개수 |
| 001 | 사이다 | 1300 | 1 |
| 001 | 빵 | 1000 | 3 |
| 001 | TV | 1300000 | 1 |
| 002 | 우유 | 4000 | 1 |
| 003 | 치즈 | 2000 | 2 |
| 003 | 수건 | 3000 | 10 |
연관성(동시/같이 구매)이 높은 물품들이 무엇일까
ch1. 분석모형 설계
(1) 분석절차 수립
| 01 | 분석모형 선정 | ||
| 분석모형 선정 필요성 분석모형 선정 프로세스 - 문제요건 정의 또는 비즈니스 이해에 따른 데이터 선정과 분석 목표/조건 정의 - 데이터 수집, 정리 및 도식화 - 데이터 전처리(데이터 정제, 종속/독립변수 선정, 데이터 변환, 데이터 통합, 데이터 축소 등) - 최정의 분석모형 선정 |
|||
| 02 | 분석 모형 정의 | ||
| 1. 분석 모형의 정의와 종류 : 예측, 현황진단, 최적화 2. 분석 모형 정의를 위한 사전고려사항 - 필요성, 파급효과, 추진시급성, 구현가능성, 데이터 수집가능성, 모델 확장성 - 하향식, 상향식 접근 |
|||
| 03 | 분석모형 구축절차 | ||
| 1. 분석 시나리오 작성 2. 분석 모형 설계 - 분석모형 설계시 사전 확인 사항 - 분석 모델링 설계와 검정 - 분석 모델링에 적합한 알고리즘 설계 : 비지도학습, 지도학습, 준지도학습, 강화학습 - 분석모형 개발 및 테스트 3. 분석 모델링 설계와 검정 4. 분석 모델링 설계와 검정 – 추정방법에 대한 기술 검토 |
|||
(2) 분석 환경 구축
| 01 | 분석 도구 선정 | ||
| 1. R/파이썬 2. 기존 프로그램(sas 등) |
|||
| 02 | 데이터분할 | ||
| 1. 데이터 분할 정의 : 학습용, 평가용, 검증용 2. 과대적합과 과소적합, 일반화 |
|||
학습용: 일부 데이터로 모형을 만들어 결과를 나머지 데이터와 비교
ch2. 분석기법 적용
(1) 분석기법
| 01 | 분석기법 개요 | ||
| 1. 학습유형에 따른 데이터 분석 모델 : 지도학습, 비지도 학습, 준지도학습, 강화학습 | |||
지도학습: 병(암), 이미지 분류
비지도학습: 패턴
| 02 | 회귀분석 | ||
| 1. 특정변수(독립)가 다른 변수(종속)에 어떤 영향을 미치는 지를 수학적 모형으로 설명,예측하기 위한 기법 2. 모형식, 추정방법, 회귀모형 진단(적합도검정, 변수의 영향력분석, 잔차분석), 회귀계수의 해석 3. 선형회귀분석 : 단순회귀분석, 다중 선형회귀분석 선형회귀분석의 기본적인 가정 : 선형성, 잔차정규성, 독립성, 잔차 등분산성, 다중공선성 4. 로지스틱 회귀분석 : 단순 로지스틱(종속변수 범주 2개), 다중로지스틱(종속변수 범주 3개이상) |
|||
아파트가격 = X * 평형
| 03 | 의사결정나무 | ||
| 1. 의사결정규칙을 나무 모양으로 나타내어 전체 자료를 몇개의 소집단으로 분류, 예측을 수행하는 기법 2. 의사결정나무의 구성 : 뿌리, 중간, 끝, 자식, 부모, 가지, 깊이 3. 의사결정나무의 종류 : 분류나무, 회귀나무 → 분류 기준 4. 의사결정나무 분석과정 : 변수선택 → 의사결정나무 형성 → 가지치기 → 모형평가 및 예측 5. 의사결정나무 대표적 알고리즘 -CART, C4.5/C5.0 /CHAID/랜덤포레스트 6. 의사결정나무의 장단점 |
|||
과적합 방지 -> 데이터 분할
장점: 연속형&범주형 변수 모두 적용, 변수 비교 가능, 규칙 이해 쉬움
단점: 트리 복잡해지면 예측력 낮아짐, 데이터에 의존적임
| 04 | 인공신경망 | ||
| 1. 특징 : 인간의 두뇌 신경세포인 뉴런을 기본으로 한 기계학습 기법 2. 인공신경망의 발전 - 기존 신경망 다층 퍼셉트론이 가진 문제 : 사라지는 경사도, 과대적합 - 딥러닝의 등장 3. 인공신경망의 원리 : 지도학습, 비지도 학습, 강화학습 4. 학습 - 손실함수 - 평균제곱 오차 - 교차엔트로피 오차 - 학습알고리즘 - 오차역전파 - 활성화 함수 - 과대적합(과적합) 및 해결방안 (규제방안) 5. 딥러닝 모델 종류 : CNN, RNN, LSTM, 오토인코더, GAN |
|||
| ID | 신용등급 | 신용기간 | 연령 | 직업 | 과거 연체 여부 | 연봉 |
레이어와 비선형으로 인한 과적합
손실함수 -> 사라지는 경사도 문제
추정(fitting)
y가 연속형이면 평균제곱 오차, 0또는1이면 교차엔트로피 오차
CNN: 신경네트워크의 한 종류, 한 사람의 시신경 구조를 모방한 구조, 완전 결합,
RNN: 순서를 가진 데이터를 입력, 단위간 연결을 시퀀스 통해 연결
LSTM: 게잍가 3가지, 입ㄹ갸, 출력, 망각을 통해서 가중치를 통해서
!!! 오토인코더: 이미지, 비지도 학슺 모델, 닻원의 데이터를 저차원의 데이터로, 저치워를 고차원으로 바꿔줌
GAN: 생성자 네트워크 생성, 패턴의 진위ㅡㄹ 판별하는 팔변자 네트워크 생성(chatgpt)
| 05 | 서포터벡터머신(SVM) | ||
| 1. 개념 : 지도학습 기법으로 고차원 또는 무한 차원의 공간에서 초평면을 찾아 이를 이용하여 분류와 회귀 2. 주요 요소 : 벡터, 결정영역, 초평면, 서포트벡터, 마진 3. 핵심특징 : 여백(마진) 최대화로 일반화 능력 극대화 4. 장단점 |
|||
| 06 | 연관성 분석 | ||
| 1. 둘이상의 거래 또는 사건에 포함된 항목들의 관련성을 파악하는 탐색적 데이터 분석 기법(장바구니 분석) 2. 연관규칙 순서 - 데이터간 규칙 생성 - 규칙에 대한 지지도, 신뢰도, 향상도 산출 - 규칙의 효용성 평가 3. 연관규칙 계산 알고리즘 : 아프리오리 알고리즘 4. 연관성 분석의 장단점 |
|||
왜 연관성 분석을 하는지 알아야 함
| 07 | 군집분석 | ||
| 1. 주어진 각 개체들의 유사성을 분석해서 유사성이 높은 대상끼리 일반화된 그룹으로 분류하는 기법 2. 기본가정 : 개체특성 동일, 거리기준 분류, 군집특성은 개체들의 평균값 3. 군집분석 척도 : 유클리드 거리, 맨하튼 거리, 민코우스키 거리, 마할라노비드 거리, 자카드 거리 4, 군집분석의 종류 - 계층적 군집분석 : 계층적 병합 군집화, 최단연결법, 최장연결법, 평균연결법, Ward 연결법 - 비계층적 군집분석 : K-means 군집분석, 밀도기반 클러스터링, 확률분포기반 클러스터링 5. 군집분석의 장단점 |
|||
Cluster(유사한 집단):
분석: why? -> 개인화 -> 초개인화
거리로 분석: 데이터 간의 거리 -> 피타고라스의 정리로 거리 구함 => 유클리드 거리(c)
맨하탄 거리: a^2 + b^2 = c^2에서 a+b
계층적 군집 분석: 시험(거리주고 군집 개수 맞추기)
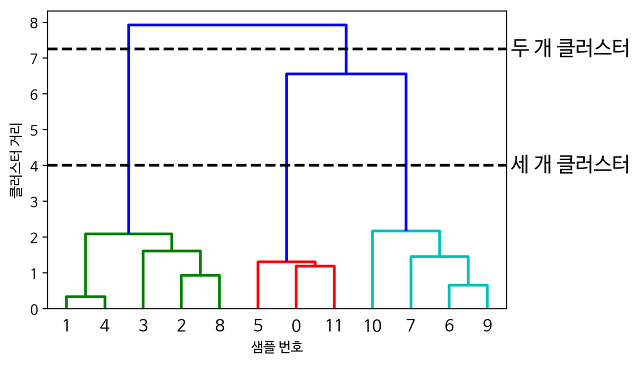
비계층적 군집분석: K-means(K가 군집) -> 군점수 -> 1. 임의의 값 각 개체 간 거리 구하기 2. K1 K2 집단의 평균
=> 단점: k를 미리 결정할 수 없음
같은 군집 내에서의 개체들은 동질적이어야 하고 서로 다른 군집의 데이터들끼리는 최대한 이질적이어야 분석이 잘 된 것이다
-> 비지도 학습

(2) 고급분석기법
| 01 | 범주형자료분석 | ||
| 1. 범주형 자료 분석의 통계적 정의 2. 자료의 분석 - 자료의 형태에 따른 범주형 자료분석 방법 - 분할표 : 비율차이, 상대적위험도, 오즈비 - 빈도분석 - 교차분석 카이제곱 검정 - 로지스틱회귀분석 - t-검정 - 분산분석 |
|||
자료형: 연속형(양적자료; 사칙연산 가능 => 크기 비교) | 범주형(질적자료; 그룹 나누기)
자료의 탐색 방법이 달라짐:
but 혼합된 자료도 존재:
| 분반 | 중간고사 성적 |
| A | |
| B | |
| C |
=> 분반에 따른 평균 = >
분반 2개 비교: t-검정
분반 3개 비교: F-검정
범주형 자료 분석
그림: 스캐터플롯 - 수치: 피어슨의 상관계수
| 02 | 다변량 분석 | ||
| 1. 다변량 분석의 용어 : 종속기법, 상호의존적 기법, 명목척도, 순위척도, 등간척도, 비율척도 정량적 자료, 비정량적 자료, 변량 2. 다변량 분석기법의 분류 - 다중 회귀분석 - 다변량 분산분석, 다변량공분산 분석 - 정준상관분석 - 요인분석 - 군집분석 - 다중판별분석 - 다차원척도법 |
|||
다변량: 여러 개수의 연관성 분석
| 03 | 시계열분석 | ||
| 1. 시계열자료 특징 2. 시계열 자료 : 불규칙성분 + 체계적성분(추세, 계절, 순환) 3. 정상성의 조건 : 평균일정, 분산일정, 공분산 시차에 의존하지 않음 4. 시계열자료 분석방법 - 단순방법 : 이동평균법, 지수평활법, 분해법 - 모형기반 : 자기회귀, 자기회귀이동평균, 자기회귀누적이동평균 - 이해와 제거의 목적 : 스펙트럼 분석, 개입분석 |
|||
시계열(time series): 관측치 -> 일정한 장소|시간|단위 측정
데이터의 ID가 시간으로 변경
| Time | 관측값 |
GDP(매년, 매월 - 특정 지역), 기상(매시간)
시계열의 체계적 성분:
1. 추세(trend)를 가지고 있는지 -> 증가 | 감소
a. 평균의 변화가 있어야 함! => 구간 나누고 전체 평균과 각 구간의 평균을 구한다 => 평균이 다르면 트렌드가 존재
2. 시즌(계절성; seasonality): ex) 빼뺴로 판매량(12개월; 11월 11일마다)
3. 사이클(순환주기):
목적: 예측(관측 시점 이후의 예측 시점) | 관측 시점의 패턴으로 모형을 만듦
불규칙 성분에 있는 애들 정상성(stationary)을 만족해야 함 [평균, 분산 일정해야 함 / 시차간의 의존성이 없어야 함] => 모형화 가능
시험: 어떤 모형인지, 체계적 성분 무엇, 정상성이 무엇
관측기간
- 규칙성분: 추세, 계절, 순환
- 불규칙: 모형화
자기회귀(Auto-Regression): Yt = Yt-1 + Et-1
Moving-average:
ARMA
| 시간 | Yt | Yt-1 |
| 1 | 3 | |
| 2 | 7 | 3 |
| 3 | 4 | 7 |
전시차의 값으로 예측
| 04 | 베이즈 기법 | ||
| 1. 베이즈 추론 : 확률론적 의미, 베이즈 기법의 개념 2. 베이즈 기법 적용 - 회귀모형에서의 베이즈 기법 적용 - 분류에서의 베이즈 기법(나이브 베이즈 분류) |
|||
Bayes: 과거의 경험치까지도 추론에 사용
| 05 | 딥러닝 분석 | ||
| 1. 딥러닝 분석의 개념 - 인공신경망의 문제점과 딥러닝의 개선점 2. 딥러닝 분석 말고리즘 - 심층신경망(DNN) - 합성곱신경망(CNN) - 순환신경망(RNN) - 심층신뢰신경망(DBN) |
|||
특성 숙지
시험: ~~에 관련된 딥러닝 기법이 무엇인가
| 06 | 비정형데이터분석 | ||
| 1. 비정형 데이터의 개요 - 데이터 수집의 난이도, 데이터 처리의 아키텍쳐, 잠재적 가치 2. 비정형데이터 분석 - 비정형 데이터 분석 기본 원리 - 데이터 마이닝 - 텍스트 마이닝 - 웹 마이닝 - 오피니언 마이닝 |
|||
시험: 신뢰도 / 지지도 구하는 문제
https://fintechpark.tistory.com/12
[ADsP] 3과목 필독! 연관분석의 지지도, 신뢰도, 향상도
연관분석이란? ADsP 시험에서 개념은 2문제, 계산도 약 1~2문제 출제 되는 연관분석의 지지도, 신뢰도, 향상도! 연관규칙이란 항목들 간의 조건-결과로 이루어지는 '패턴'을 발견하는 것이며, 상품
fintechpark.tistory.com
| 07 | 앙상블모형 | ||
| 1. 앙상블 분석의 이해 2. 앙상블 분석의 종류 - 보팅(voting) : 투표방식을 통해 결정 - 부스팅 : 가중치를 활용하여 연속적인 약 학습기를 생성하고 이를 통해 강학습기를 만드는 방법 - 배깅 : 샘플을 여러번 뽑아 각 모델을 학습시켜 결과를 집계하는 방법 |
|||
보팅: 제일 많은 것으로
시험: 여러개의 모형 앙상블 => 가중치를 활용하여 ~~강학슺기를 만드는 방법은? 부스팅
| 08 | 비모수 통계 | ||
| 1. 모수(매개변수, 파라미터)의 정의 2. 비모수 통계의 개념 3. 비모수 통계의 사용 조건 4. 비모수 통계의 특징 5. 비모수적 통계 검정법 : 부호검정, 월콕슨 부호순위 검정, 만위트니 검정, 크루스칼왈리스 검정 |
|||
검정법 용어만 알고 있으면 됨
모수의 어떤 가정을 하지 않고 하는 검정은?
1. t검정
2. F검정
3. 카이제곱검정
4. 윌콕슨 검정
답: 4
빅데이터 분석기획 → 빅데이터 탐색 → 빅데이터모델링→ 빅데이터 결과해석
| Part4 : 빅데이터 결과 해석 |
분석모형 평가 및 개선 → 분석결과 해석 및 활용
| Hot keyword | |||
| 편향, 분산, 혼동행렬, ROC, F1 score, 적합도 검정, 민감도, 특이도, 모형진단, 잔차진단, 정규성가정, 홀드아웃, 초매개변수, 모형선택, 매개변수 최적화 MAE, MAPE, 선형회귀, ROC, 지지도, 신뢰도 산점도, 막대그래프, 불균형데이터셋, 인포그래픽, 버블챠트, 키토그램 모델링 타입, 분석결과의 활용, 성과지표 |
|||
ch1. 분석모형 평가 및 개선
(1) 분석모형 평가
| 01 | 평가지표 | ||
| 1. 지도학습 – 분류모델의 평가지표 (오차행렬/혼돈행렬) - 정확도(accuracy) - 정밀도(precision) - 민감도 - 재현율(recall) - F1 스코어 : 정밀도와 재현율의 조화평균 - ROC : 임계값을 0~1로 주어지면서 FPR와 TPR을 그리는 방법 - AUROC : ROC 커브의 하단면적 2 지도학습 – 회귀모델 평가 지표 - SSE : 오차제곱합 - MSE : 오차제곱합의 평균 → 퍼센트 변환 MSPE - RMSE : MSE에 제곱근 → 로그 변환 RMSLE - MAE : 실제값과 예측값의 절대값 차이 → 퍼센트 변환 MAPE - 결정계수(R^2) 또는 수정된 결정계수 - AIC/SBC 3. 비지도 학습 – 군집분석의 평가 방법 - 실루엣 계수 - Dunn index |
|||
지도학습:
회귀 모형(연속형 y) - 가격예측모형 - 헤도닉모형
분류 모형(범주형 y[0,1]) - 로지스틱회귀분석 - y hat = (0~1)
| 혼돈행렬 | 실제값 | ||
| 예측값 | True | False | |
| True | True Positive (TP) 정상을 정상으로 예측 |
False Positive (FP) 거짓을 정상으로 예측 |
|
| False | True Negative (TN) 정상을 거짓으로 예측 |
False Negative (FN) 거짓을 거짓으로 예측 |
|
True면 예측 맞음 / Fasle는 예측 틀림
표 중요!!!
코로나 때 많이 사용됨 - 진단키트가 좋은지 분별(재현율=민감도)
검사가 정확했던 데이터 중 양성 데이터의 확률
https://www.medicaltimes.com/Main/News/NewsView.html?ID=1150165
믿었던 국산 코로나 진단키트의 배신…정확도 50%대 불과
코로나 대유행이 시작된 뒤 이른바 K-헬스의 선봉장으로 불리며 수조원대 수출고를 견인한 국산 체외진단기기가 실제로는 정확도가 크게 떨어진다는 연구가 나와 논란이 예상된다.허가 임상시
www.medicaltimes.com
군집 분석: 군집의 크기가 안전한지 평가
| 02 | 분석 모형 진단 | ||
| 1. 정규성 가정 진단 - 중심극한정리 - 정규성 가정 진단 : 샤피로-윌크 검정, 콜로고로프-스미로노프 검정, Q-Q 플랏 2. 잔차 진단 - 잔차의 정규성 진단 - 잔차의 등분산성 진단 - 잔차의 독립성 진단 |
|||
| 03 | 교차검증 | ||
| 1. k-폴드 교차검증 - 전체 데이터를 k개의 서브셋으로 분리하여 k-1개를 훈련데이터로 사용 1개의 서브셋 데이터를 테스트 - 과적합 방지 + 반복횟수 증가에 따른 모델훈련 평가/검증 시간 오래 걸림 2. 홀드아웃 교차 검증 - 데이터 셋을 훈련, 검증, 테스트 데이터로 지정 |
|||
과적합(오버피팅) 방지하기 위한 검증
| 04 | 적합성 검증 | ||
| 1. 적합도 검증 – 데이터가 가정된 확률에 적합하게 따르는지 검증 2. 카이제곱 검증 - 기댓값과 관측값의 차이 검증 3. 콜로고로프-스미르노프 정규성 검증 - 관측된 표본분포와 가정된 분포사이에서의 적합도 검증 (누적분포함수 활용) |
|||
모형이 적합한지 아닌지
1. 모형 선택이 옳바른지
2. x값들이 적합한지
3. 모형 전체가 설명을 잘하는지
(2) 분석모형 개선
| 01 | 과적합 방지 | ||
| 1. 모델의 낮은 복잡도 - 훈련데이터를 더 많이 확보하는 것이 가장 좋은 방법 - 정규화 - 드룹 아웃 2. 가중치 감소 - L2 규제 (릿지모델) - L1 규제 (라쏘메델) 3. 편향-분산 트레이드 오프 |
|||
신경망 -> 가중치 감소
단답형으로 많이 난옴
| 02 | 매개변수 최적화 | ||
| 1. 확률적 경사 하강법 - 최적의 매개변수 값을 찾기위해 매개변수에 대한 손실함수의 기울기를 활용 2. 모멘텀 - 운동량 3. AdaGrad 4. Adam 5. 초매개변수 최적화 |
|||
ch2. 분석모형 해석 및 활용
(1) 분석 결과 해석
| 01 | 분석모형별 결과 해석 | ||
| 모형별 결과 해석 방법 - 회귀분석 등 예측모형 : 모형의 예측력 및 회귀계수의 해석 - 분류모델 : (분류표를활용한) 모형의 성능 및 모형에 사용된 주요 변수에 대한 기여도 - 군집분석 : 내부/외부 데이터를 통한 군집의 특성, 군집의 적정성(팔꿈치기법, 실루엣기법) - 연관분석 : 품목들 간의 연관성(지지도, 신뢰도, 향상도) 및 연관품목의 의미 2. 비즈니스에 대한 기여도 평가 - 비즈니스에 도입 활용함으로써 의사결정, 프로세스의 효율성, 개선을 도출하기 되며 이에 대한 기여도 평가 - ROI(투자수익률) |
|||
모형의 성능: 정확도, 재현율...
| 02 | 분석모델별 시각화 | ||
| 1. 회귀모델 : 변수들간의 상관분석을 위해 히트맵(상관계수 테이블+상관계수에 따른 색강조) 또는 산점도 2. 분류모델 - SVM : 산점도와 구분선을 통합 비교시각화 - KNN(k-nearest Neighbor) : 비교시각화 평행좌표계를 통한 변수들과의 연관성 및 그룹데이터의 경향 - 의사결정나무 : 관계시각화 트리다이어그램 3. 딥러닝 모델 - Node link diagram for network architectures - dimensional reduction and scatter plot (차원축소, 산점도) - Line charts for temporal metrics (측정을 위한 선도표) 4. 군집분석 : 그룹 클러스터별 단위로 산점도 5. 연관분석 : 연관품목들끼리 묶어서 관계 시각화 네트워크 그래프 |
|||
(2) 분석 결과 시각화
| 01 | 데이터 시각화 개요 | ||
| 데이터 시각화 정의 : 정보를 명확하고 효과적으로 전달하기 위해 도표나 챠트 등으로 표현 데이터 시각화 특성 : 데이터에 대한 이해 직관화, 습득시간 단축 데이터 시각화 방법 - 시간 시각화 : 막대그래프, 누적막대 그래프, 점/선 그래프, 계단그래프, 추세선 - 분포 시각화 : 히스토그램, 파이챠트, 도넛챠트, 트리맵, 누적연속 그래프 - 관계 시각화 : 산점도, 버블챠트, 히트맵 - 비교 시각화 : 히트맵, 체느로프페이스, 스타챠트, 평행좌표계, 다차원척도법 - 공간 시각화 : 지도매핑, 카토그램 4. 정보 시각화/정보 디자인/인포그래픽 - 방대한 양의 정보를 한번에 사용자가 보고 이해할수 있도록 직관적으로 표현하는 방법 - 카토그램(지도도표), 분기도, 개념도, 계통도(덴드로그램), 네트워크다이어리, 트리맵, 하이퍼볼릭 트리 -인포그래픽 : 복잡한 수치나 글로 표현되어 있는 정보와 지식을 픽토그램, 챠트, 지도로 표현 |
|||
시험: 다음 중 관계를 나타내지 않는 것은?
그래프: x와 y에 무엇이 들어가는지 파악!
점/선 그래프로 추세 파악 가능
막대그래프(관측값=y, 시간=x) vs 히스토그램(빈도=y, 값=x)
히스토그램의 x축, 값의 구간을 스스로 정해야 됨 => 장점이자 단점
파이챠트: 분포 파악
트리맵: 2개의 자료를 동시에 표현 -> 분포 표현
히트맵: 관계 파악, 비교 가능
체르노프페이스: 비교
스타챠트: 비교
(3) 분석 결과 활용
| 01 | 분석모형 전개 | ||
| 빅데이터 분석 방법론 : 분석기획 → 데이터 준비 → 데이터 분석 → 시스템 구현 → 평가 및 전개 전개 단계의 역할 : 개발된 모델을 적용하여 결과를 확인하고 계속적인 관리를 위한 방법을 제시하는 단계 |
|||
| 02 | 분석결과 활용계획 | ||
| 1. 분석결과 활용계획 수립 : 빅데이터 분석 결과를 어떻게 업무에 반영할 것인지에 대한 액션플랜 수립 업무 성과를 지속적으로 모니터링 할수 있는 방안 수립 2. 분석결과 활용 시나리오 개발 3. 업무 적용 및 효과 검증 |
|||
| 03 | 분석결과 적용 및 보고서 | ||
| 1. 분석결과 적용 과 성과 평가 : 성과측정 항목 및 계획, 실제와 예상성과 지표 비교, 개선사항 도출, 공유 2. 최종 보고서 작성 : 프로젝트 개요, 수행조직, 단계별 산출물 요약, 성과 평가, 모니터링 및 개선 계획 |
|||
'Machine Learning' 카테고리의 다른 글
| Tistory<->Google Analytics (0) | 2023.12.05 |
|---|---|
| Statistics: Data Analysis and Application Using Python (0) | 2023.09.14 |
| 2023년 KISA AI+Security 아이디어 공모전 (0) | 2023.09.13 |
| TensorFlow(python) 101 (0) | 2023.09.11 |
| 머신러닝1 (0) | 2023.09.07 |


